什么是大语言模型?

2022 年底,ChatGPT 横空出世,人工智能从科技新闻走进了每个人的生活。如今,像 Deepseek 这样的助手已经能帮你写邮件、改代码、做翻译——但你有没有想过,它到底是怎么“听懂”你说话,又怎么给出回答的?这一切的背后,是一项叫做大语言模型(Large Language Model,LLM)的技术。它正是驱动当前这波人工智能浪潮的核心引擎。在这篇文章中,我将抛开晦涩的术语,用人人都能听懂的语言,带你理解大语言模型到底是什么,以及你每天使用的 AI 助手究竟是如何工作的。
什么是人工智能
我们认为人类还有一些动物是具有智能的,它们能够根据环境适应自己的行为。而早年的一些机器是没有智能的,它必须要人工去操作它。比如一个洗衣机,我们必须放入衣服,然后设置洗衣模式,然后洗衣机开始工作。这个洗衣机是没有智能的,它只是按照我们设定的程序去执行。
后来人们希望机器能够拥有智能,最直接的体现就是人类能和它交流。这个交流可以是通过文字的交流,也可以是通过语音的交流。现在几乎每个人都有智能手机,虽然说是智能手机,但很多时候其实你感受不到太多智能,它只是基于你的点击来做出相应的反应。很多手机都自带了一些语音助手,你可以告诉语音助手,让它帮你打电话、发短信、设置闹钟等等,它都可以帮你去完成这些工作,此时我们会觉得手机具备了智能。
人们通过各类技术,让不具备智能的机器表现得好像具备智能一样,这类技术就叫做人工智能技术。而现在人们通常用人工智能去指代一些看上去具有智能的系统,比如我们会说 Deepseek 是人工智能。通俗来讲,人工智能就是人工制造的智能,与之相对的就是动物所具备的那种天然的智能。
你可能听到过人工智能、深度学习、机器学习、大语言模型等词汇。下面由 AI 生成的这张图,形象地解释了它们之间的关系:
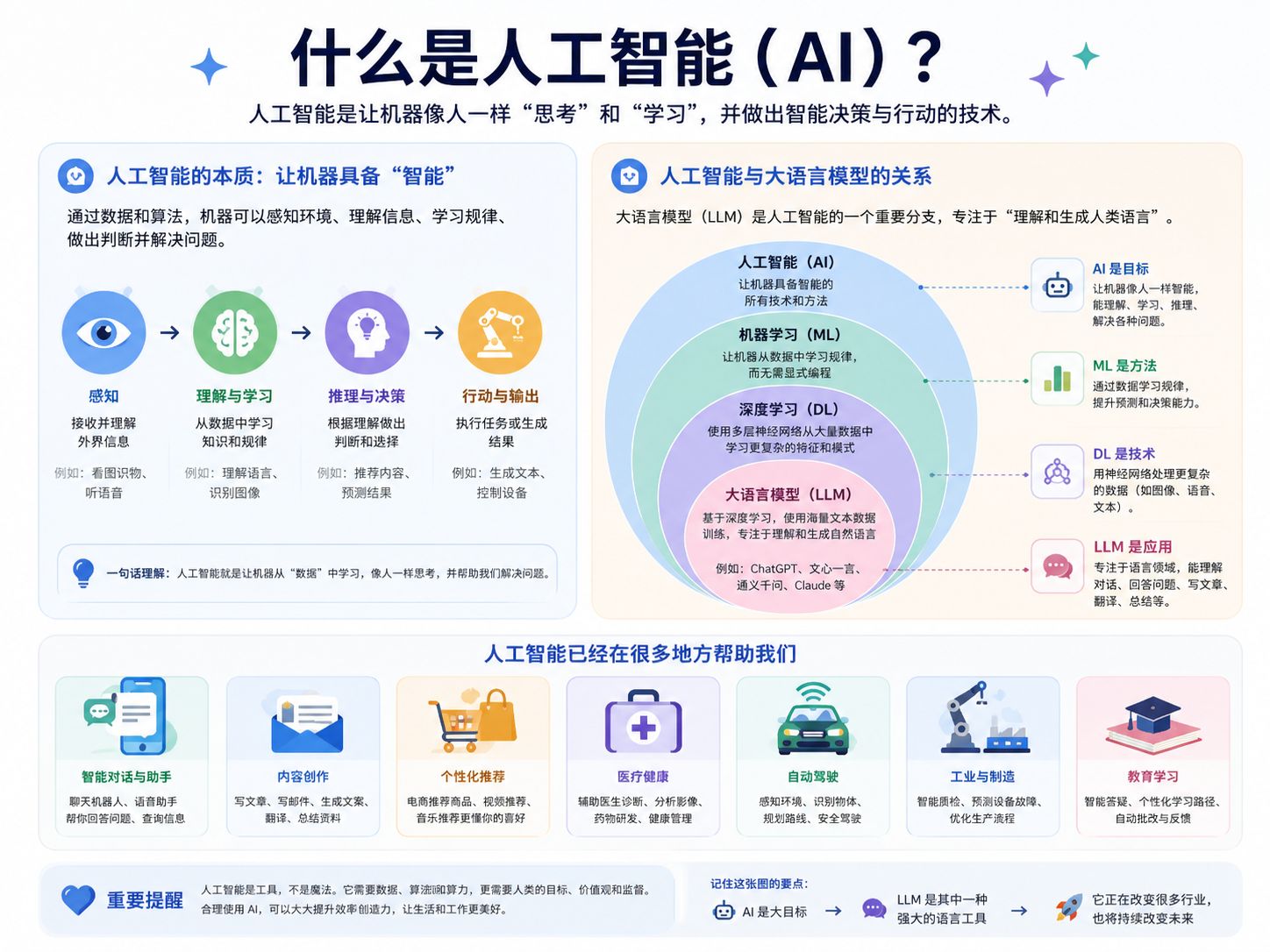
这几者的关系非常复杂,涉及到很多技术细节,如果不理解也没有关系。人工智能技术是一个大类,它泛指那些能够让机器拥有智能的技术。其中使用到的一个技术叫做机器学习,机器学习就是让机器能够从数据中寻找到规律的一种技术。而深度学习又是机器学习中的一个子分支,它是通过构建深层神经网络来实现机器学习的一种技术。大语言模型是深度学习中的一个应用领域,它通过构建一个非常大的神经网络来实现对语言的理解和生成。
什么是模型
大语言模型首先它是一个模型,这里我们首先要明白什么叫模型。模型在不同的语境下有不同的含义,比如说我们常常会说飞机模型,数学模型,或者思维模型。飞机模型就是缩小版的飞机,它可以用来展示飞机的结构和外观。数学模型就是从数学的角度去刻画一个现象,比如说我们可以用一个方程来描述一个物理现象,这个方程就是一个数学模型。而思维模型就是我们在思考的时候采用了一种方法论。
人工智能领域中的模型通常和数学模型的概念比较接近,它是用来描述现实世界中某种规律的数学公式。我们可以通过这个模型来理解现实世界中的某些现象,或者预测未来的某些现象。模型是对现实世界的一种抽象,它用一些数学的符号和公式来表达现实世界中的规律。
比如我们现在需要做一个天气预测系统,我们输入的数据有以下几个:
- :温度
- :湿度
- :风速
- :气压
当人类在做天气预测的时候,他会综合考虑以上这些因素,每个因素对于天气的影响可能是不同的。因此我们可以对这个天气预测过程进行建模,它的模型如下:
这里 、、 和 就是每个因素的权重。这个模型的输出 就是一个分数,表示预测天气会下雨的概率。
气象站会收集大量的历史天气数据,这些数据包含了温度、湿度、风速、气压等因素,以及最终的天气情况(比如是否下雨)。通过这些历史数据,我们可以求出模型中的权重 、、 和 ,使得这个模型能够尽可能准确地预测天气是否下雨。而这个找到模型权重的过程,就可以视为训练模型的过程。
下面是我让 AI 助手帮我画的一张用于解释模型的示例图:
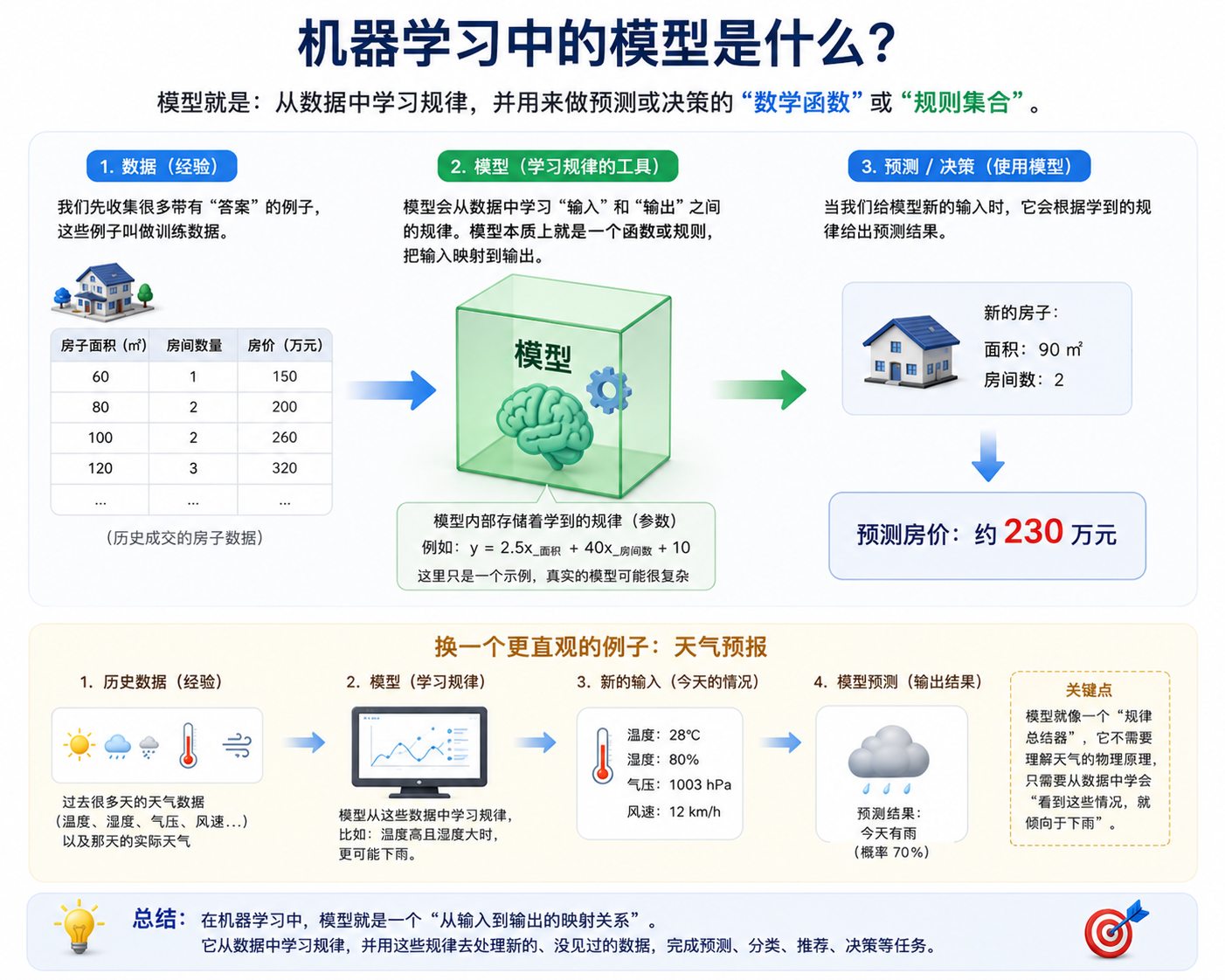
在图中它举了两个例子,一个是用模型去预测房价,另外一个是去预测天气。在预测房价的例子中,会对房子的面积和房间的数量与房子价格之间的关系进行建模,模型的输出就是一个房价的预测值。在预测天气的例子中,会对温度、湿度、风速和气压与天气情况之间的关系进行建模,模型的输出就是一个降雨概率的预测值。
什么是语言模型
前面我们知道了模型的概念,它将现实中的某种规律,用数学公式的方式来表达出来。而语言模型其实就是用来描述语言规律的模型。人类的语言是很复杂的,比如我个人学习了十几年的英语,也没有学会。但是如果你仔细考虑我们的语言,就会发现语言中是有规律的。比如当我说了“我想吃”这三个字之后,接下来我很有可能会说的是一种食物的名称,比如“我想吃苹果”、“我想吃米饭”。而我基本不会说 “我想吃混凝土”、“我想吃钢筋”。
语言模型就是基于前文来预测下文的一类模型。我们在使用手机输入法的时候,就会使用到语言模型的技术。当你输入了三个字“我想吃”之后,输入法就会给你推荐一些食物的词语,比如“苹果”、“米饭”。而如果它给你推荐的是“混凝土”、“钢筋”,你会果断卸载这个输入法。
假如我们输入的文本序列为 ,语言模型的目标就是根据前面已经输入的文本序列 来预测下一个文本 。这个预测过程可以用概率的方式来表达:
这里 表示在条件 的情况下事件 发生的概率。上面的语言模型公式的意思就是,在已经输入了文本序列 的情况下,预测下一个文本 的概率。
比如当我们输入了“我想吃”这三个字之后,语言模型会计算在这个条件下,接下来出现“苹果”的概率,出现“米饭”的概率,出现“混凝土”的概率,出现“钢筋”的概率等等。
- P(米饭|我想吃) = 0.3
- P(苹果|我想吃) = 0.2
- P(混凝土|我想吃) = 0.01
- P(钢筋|我想吃) = 0.01
- ...
上面的例子中,语言模型计算出在输入“我想吃”这个条件下,接下来出现“米饭”的概率是 0.3,出现“苹果”的概率是 0.2,而出现“混凝土”和“钢筋”的概率都非常低,只有 0.01。语言模型的这个特性,可以有很多实用的应用场景。
输入法可以把你已经输入的文本序列输入给语言模型,经过语言模型的计算,得到所有候选词可能作为下一个词的概率。输入法可以把概率最高的那几个词推荐给你作为候选词。
语言模型还有很多应用,比如它可以帮你纠正文本中的错误。比如你输入了“我想吃米饭”,但是你打错了,输入成了“我想吃米发”,语言模型就可以根据上下文来判断“米饭”这个词的概率更高,从而帮你纠正这个错误。
在使用机器翻译的时候,也可以使用语言模型来提供更好的翻译效果。比如当我们在从英文翻译成中文的时候,语言模型可以帮我们评价翻译出来的句子是否符合中文的语言习惯,最终会在多组候选词中选择更符合中文习惯的表达。
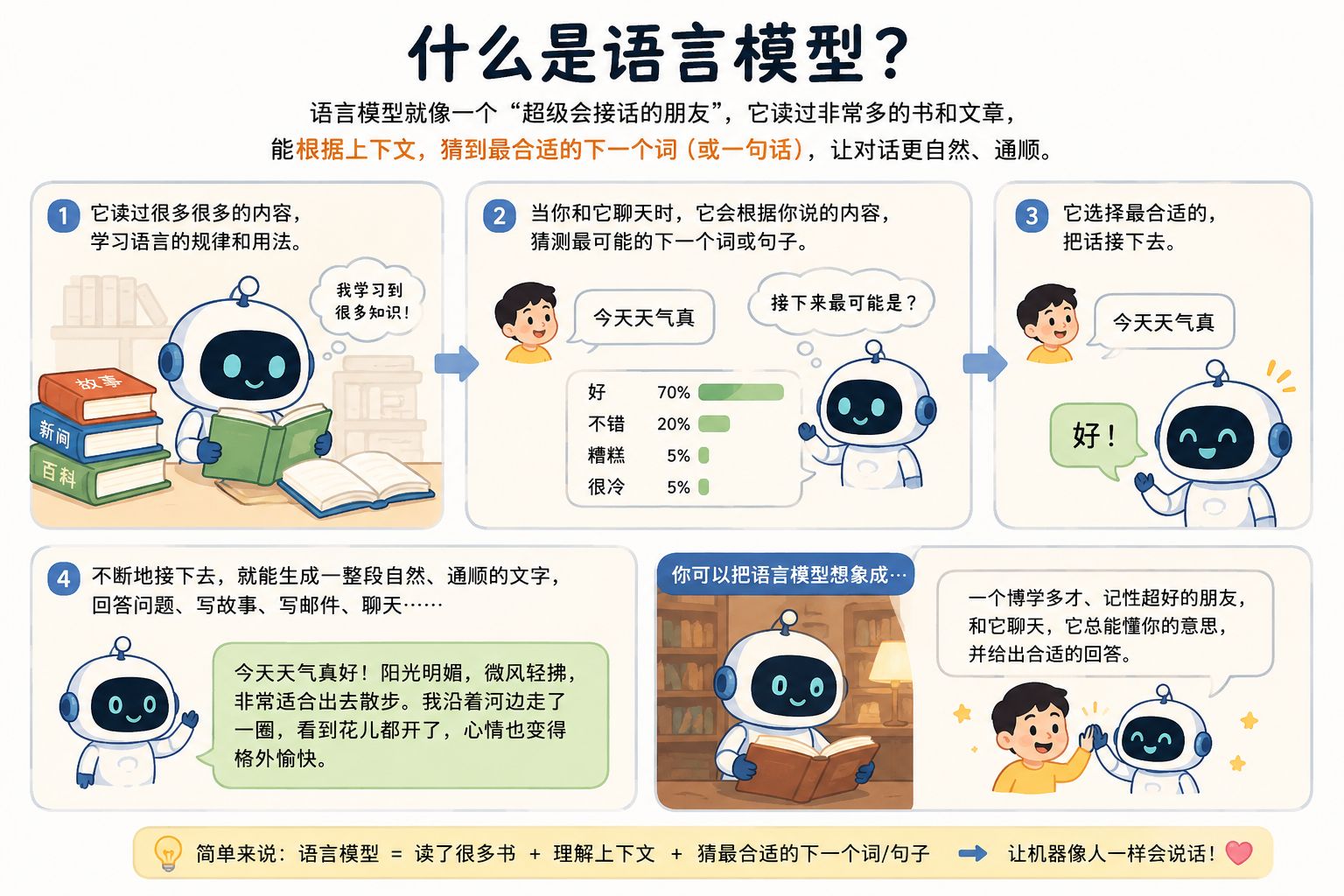
看够了文字描述?下面是我让 AI 助手帮我画的一张用于解释语言模型的示例图:
什么是大语言模型
首先我们知道语言的模式是非常复杂的,想要对复杂的语言进行建模,它的模型也会很复杂。如果我们想要建模人类的语言,就需要一个非常复杂的模型,这个模型可能会有成千上万个参数。大语言模型就是指那些具有大量参数的语言模型,我们将语言模型表示为 。现在全球很多科技公司每年投入几十亿甚至上百亿美元,他们的目的就是为了得到这个 。
大语言模型结构在过去这些年发生了很大变化,但它们解决的问题都是一样的。为了不牵扯太多技术细节,这里我不再展开描述模型的细节。我们只需要知道目前我们每天都在用的这些模型中,包含的参数高达上百亿。这些参数如果存储在你的电脑上,需要几百 GB 的空间。很多人现在的电脑都是 512 GB 的空间,如果想把这些模型的参数存在你的电脑上,很可能你的电脑都存不下。
总结来看,大语言模型就是一个包含了大量参数的语言模型,它通过大量的数据学习了语言规律,并且学习了用户表达习惯,它的本质是基于上下文来预测下一个字符的概率分布。大语言模型实际上并不理解人类的意图,它只是通过大量的数据学习到了语言文字之间的关系,从而能够通过上下文信息,预测出最有可能输出的字符。
你可能会疑惑,如果大语言模型只是一个基于上下文来预测生成下一个字符的模型,那么它为什么能够完成对话呢?我们人类在交流的时候,并不是在做成语接龙的游戏,我们会理解你说的话,给你合理的回复。大语言模型是怎么做到这一点的呢?下面我们就来解释一下这个问题。
大语言模型为何能完成对话
如果语言模型仅仅是通过前文来预测下一个字符的概率,那么这个模型按理说只会完成像成语接龙这样的游戏。但是现在的人工智能助手并不是在和你玩成语接龙的游戏,看起来像是会理解你说的话,然后给你合理的回复。大语言模型是怎么做到这一点的呢?
早期从技术圈传出来的技术名词叫做大语言模型(Large Language Model,LLM),但后来在中文互联网上,人们通常把它称为大模型(Large Model)。我认为这里存在一定的合理性,因为我们实际使用的模型,它表现的行为已经不太像是一个语言模型了。但如果你看完我的这一节的解释,你会发现它其实还算是一个语言模型。
当你最初了解了语言模型的定义之后,你会觉得它就是在做接龙。你会觉得当你输入“今天天气很好”的时候,语言模型会基于这个输入来预测下一个字的概率。它可能会预测出“今天天气很好,适合出去玩”,也可能会预测出“今天天气很好,适合在家里休息”。因为这样的输出,看起来才是连贯的语言表达。
而如果你和大模型说,今天天气很好。大模型的输出可能是“是啊,今天天气真的很好,你有什么计划吗?”这个是符合人类期望的回答,但它的输出好像和你的输入不连贯。这是因为我们在考虑语言模型的时候,都是在用文章来考虑问题。我们会觉得一篇文章中的每个句子都应该是承接上下文的,都应该是连贯的。我最早也有这样的困惑,那是因为我在很多年前学习语言模型的时候,我了解到语言模型都是通过大量的文章来训练的,所以我就觉得它的输出应该也是文章的形式。
但假如我们在训练语言模型的时候,给它提供的是对话形式的数据呢?比如下面的例子:
用户: 西安有哪些必去景点?
助手: 西安的必去景点包括秦始皇陵兵马俑、大雁塔、华清宫和西安城墙。前两个适合了解历史文化,后两个适合夜游和欣赏仿古建筑。我们可以使用大量的对话来训练语言模型,所谓的训练,就是给模型指定的输入,并期望它调整参数,得到指定的输出。因为模型的参数是在训练过程中动态调整的,只要我们限定了模型的输入和输出,模型在训练过程中就可以自适应地调整参数来满足我们指定的输入输出关系。
我们通过大量的对话来训练模型,模型就会学会在输入是一个问题的时候,输出一个合理的回答。这样我们就得到了一个能够进行对话的大语言模型了。
我们还可以给模型输入多轮对话的历史记录,让模型基于多轮对话的历史数据来预测下一轮的输出。比如我们输入:
用户:今天天气很好。
助手:是啊,今天天气真的很好,你有什么计划吗?
用户:我想去公园散步,有什么好建议吗?模型就会基于这三轮对话的历史记录来预测下一轮的输出。它可能会输出“公园里有很多花开了,适合拍照哦!”或者“公园里有个湖,适合划船哦!”等等。
看到这里你应该明白了,大语言模型实际上还是个语言模型,只不过我们在训练的时候提供给它了对话形式的训练数据。因此它在接收一个问题的时候,它可以给出回答。在使用大语言模型的时候,我们给的输入大致如下:
用户:今天天气很好。
助手:是啊,今天天气真的很好,你有什么计划吗?
用户:我想去公园散步,有什么好建议吗?
助手:大语言模型根据输入的内容就会补全这段话,它补全的内容就是助手的回答了。我们在训练大语言模型的时候,给它提供了大量的对话数据,这些对话数据可能是从互联网上爬取的,也可能是从一些对话平台上收集的。通过这些对话数据来训练模型,模型就学会了在输入一个问题的时候,输出一个合理的回答。
大语言模型是如何训练出来的
这里面我们再进一步深入了解一下模型究竟是怎么训练出来的,为什么我们在网上会看到有的公司训练一个模型需要花费上百万美元?为什么现在训练模型的工程师的薪资能够达到几百万?这里我只是从一个非常高层次的角度来解释一下模型的训练过程,对于很多细节我不会在这里讲,因为我也不一定懂很多细节。
我们前面提到过,模型的训练就是通过调整模型的参数来使得模型能够满足我们指定的输入输出关系。我们在训练模型的时候,会给它提供大量的训练数据,这些训练数据是由输入和输出组成的。比如在对话训练中,我们的输入可能是一个问题,输出可能是一个回答。
网络上大量存在的文本包括新闻稿、文章,以及历史上积累下来的书籍、论文,它们基本都是文章类型的。而大量对话数据涉及到用户隐私,在互联网上很难获得,而自己去构造对话数据的成本也很大。所以现在模型训练的过程一般都有两个阶段,第一阶段是预训练阶段,第二阶段是微调阶段。
预训练
预训练阶段是指我们先使用大量的文章数据来训练一个语言模型,这个模型的目标就是根据前文来预测下一个文本。这样的训练数据太好获取了,无论是书籍、论文、互联网上的文章,都满足训练需求。目前常见的大语言模型通常都需要在预训练阶段使用几万亿字符的文本数据。
下面就是一个大语言模型的预训练使用的数据集的示例:
这个数据有 30 多个 GB,其中包含 1000 多万篇文章。
预训练完成后,模型就可以基于前文来进行文字接龙了。可以简单思考一下,要想能够完成文字接龙的游戏,你需要掌握很多语言的基本模式的。因此在预训练阶段,使用大量比较容易获取的样本,可以让模型初步具备语言能力,掌握语言中一些通用的模式。
微调
经过预训练的模型具备了一定的语言能力,但是它并不能完成对话。接下来我们需要在预训练后的模型上进行一个微调,所谓微调就是对参数进行轻微的调整。对于一个已经会说话的人而言,再教他说相声,他就会更容易学会。同样的道理,预训练就相当于学会说话,微调就相当于让它学会多样的语言表达方式。
微调阶段会使用一些指令数据,让模型帮忙回答一些问题,或者让模型帮忙写一些文本。比如下面是一些指令数据的示例:
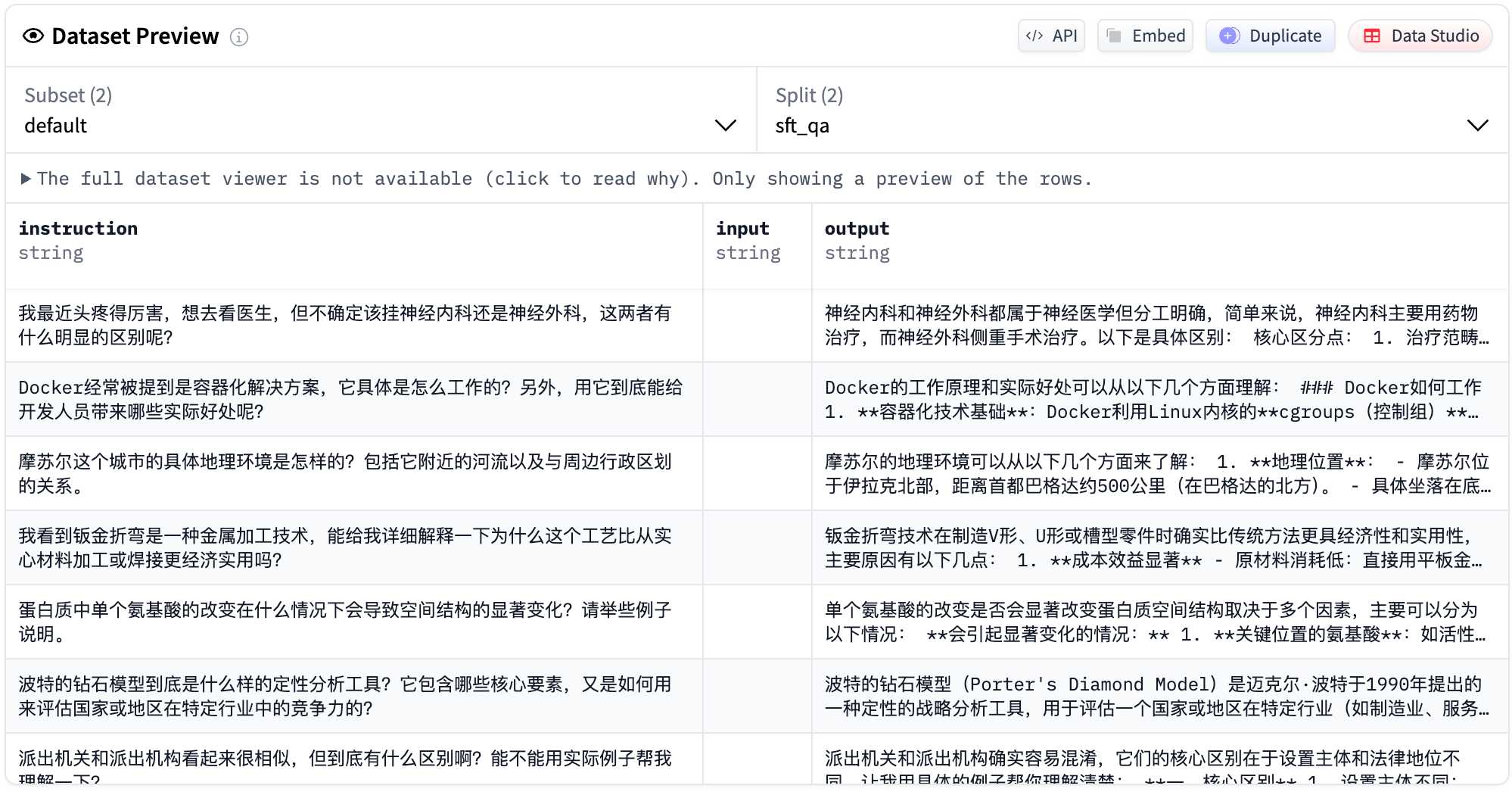
微调阶段还会使用一些问答数据,让模型学会在输入一个问题的时候,输出一个合理的回答。比如下面是一些问答数据的示例:

还会使用包含多轮对话的训练数据,让模型能够参考历史对话记录来预测下一轮的输出。比如下面是一些多轮对话数据的示例:

微调阶段通常不需要太多样本,只需要几万至十万条样本就可以了,但是这些样本必须要是一些高质量的问答数据和对话数据。经过微调之后,模型就学会了对话。
微调之后的模型依然是基于前文来预测下文,只不过微调的过程改变了模型的参数,同时改变了输入和输出的映射规律。比如在预训练阶段,模型可能会学会在输入“今天天气很好”之后,预测出“适合出去玩”这个文本。而在微调阶段,我们给它提供了大量的对话数据,让它学会在输入“今天天气很好”之后,预测出“是啊,今天天气真的很好,你有什么计划吗?”这个文本。
经过微调后模型就能理解人类的“指令”(Prompt,也叫做提示词),并输出符合格式的“回答”,模型从一个“文字续写机”转变成了“AI助手”。
偏好对齐
微调之后的模型虽然能够完成对话了,但它的输出可能会存在一些问题。因为模型是基于人类产生的文字训练的,而这些文字中有的内容可能存在一些偏见或者不符合主流价值观的内容。为了让模型的输出更符合人类的期望,我们还需要对模型进行一个偏好对齐的过程。
对齐的过程是让模型的输出对用户更有用,让模型更加礼貌,避免输出暴力内容。这就要求模型不再是简单地输出最有可能的下一个字符。而是要在输出的过程中,考虑到人类的价值观和期望。这个过程中通常需要专门的数据来对模型进行偏好对齐训练,使用到的数据集通常是由人工标注出来的,所以成本会比较高。下面是一个例子:
{
"prompt": "我应该如何对待和我意见不合的同事?",
"chosen": "对待意见不合的同事,建议保持专业和理性。首先倾听他们的观点,寻找共同点,并在私下进行建设性的沟通,以解决分歧,确保团队目标的达成。",
"rejected": "直接无视他们。如果他们在会议上反对你,你就应该用更激烈的言辞反驳回去,让他们知道你才是对的,不要给他们留面子。"
}在这个例子中,我们给模型提供了一个问题“我应该如何对待和我意见不合的同事?”,这个时候我们更希望模型选择“chosen”这个回答,而不是“rejected”这个回答。通过大量这样的训练数据来对模型进行偏好对齐训练,模型就会学会在面对类似的问题时,输出更符合人类期望的回答了。
这些数据也可以通过用户的行为来收集,比如当用户使用模型的时候,模型可以给出两种回答,然后让用户选择更好的回答。下面就是一个例子:

人工智能助手可以不断地收集用户的反馈,用于改善自己的模型效果。
大语言模型的输入与输出
当我们训练出一个模型之后,这个模型就可以用来为人们提供服务了。当我们和大语言模型交互的时候,我们的文本会被模型编码成一种特殊的格式,然后发给模型。下面是我和大语言模型交互的一个例子:
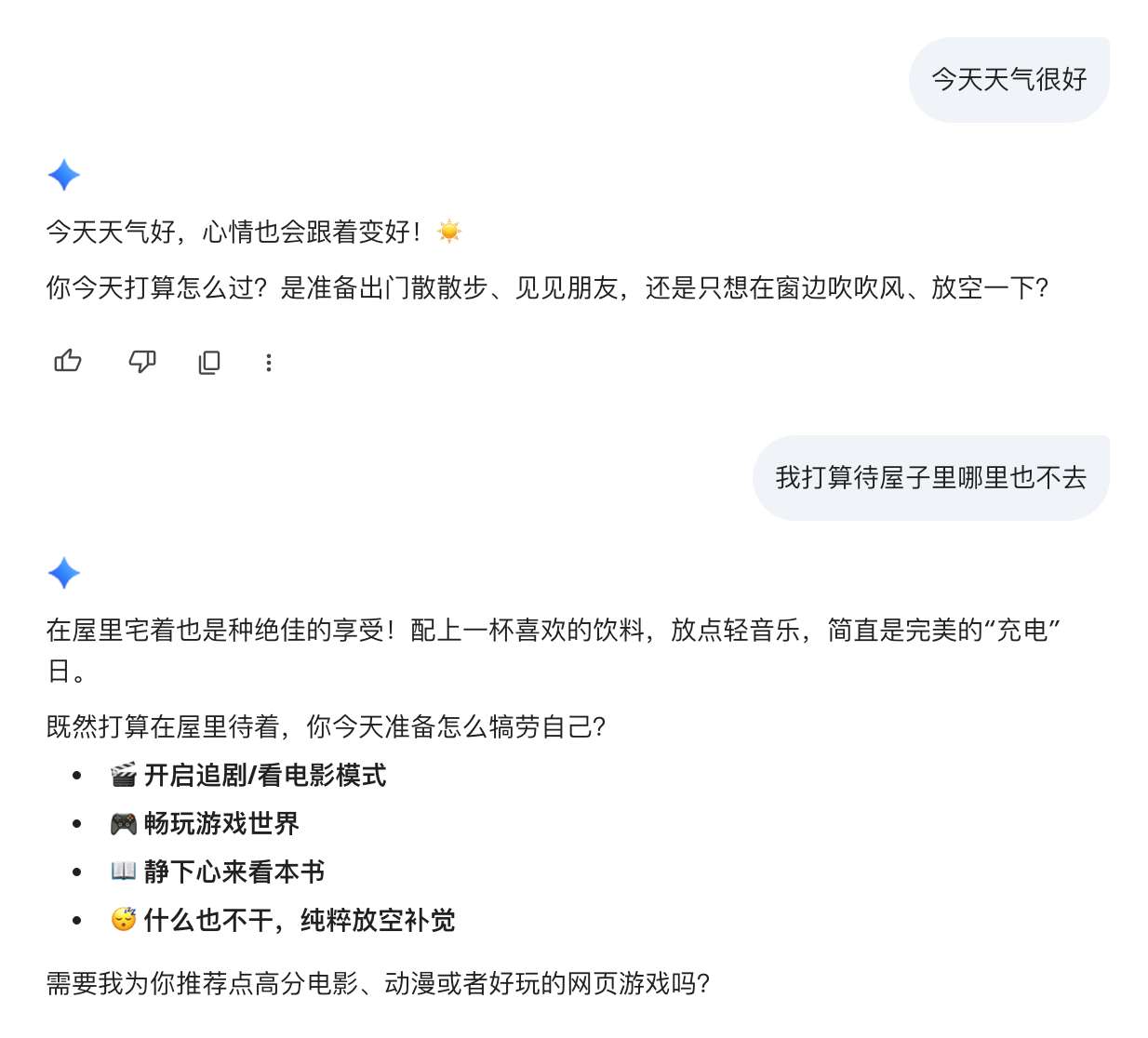
当我输入“我打算待屋子里哪里也不去”的时候,这段文本会和历史对话记录一起被编码成一种特殊的格式,然后发给模型。模型接收到的输入可能是下面这样的:
<|im_start|>system
你是人工智能助手,请用严谨且高效的方式回答用户的问题。<|im_end|>
<|im_start|>user
今天天气很好<|im_end|>
<|im_start|>assistant
今天天气好,心情也会跟着变好!☀️
你今天打算怎么过?是准备出门散散步、见见朋友,还是只想在窗边吹吹风、放空一下?<|im_end|>
<|im_start|>user
我打算待屋子里哪里也不去<|im_end|>
<|im_start|>assistant这里面 <|im_start|> 和 <|im_end|> 是一些特殊的标记,用来标记输入文本的开始和结束。<|im_start|> 后面跟着的是输入文本的角色,比如 user 表示用户输入,assistant 表示模型的回答。在训练过程中,所有的数据也是被处理成这种格式的,模型会在 <|im_start|>assistant 之后继续根据前文输出内容。模型在输出过程中,是一个字符接一个字符地输出的。当它输出一个字符之后,会将这个字符拼接到此前的输入后边,然后基于新的文本序列再次预测生成下一个字符。这个过程会一直持续下去,直到模型输出了 <|im_end|> 这个标记为止,而模型输出的这些内容就会作为 AI 助手的回复。
这里还有一个特殊的 system 角色,它用来给模型提供一些背景信息,这个信息也叫做系统提示词。比如在上面的例子中,我们给模型提供了一个 system 角色的输入,告诉它“你是人工智能助手,请用严谨且高效的方式回答用户的问题。” 那么整个模型的行为就更符合一个人工智能助手。
但是当我们在使用豆包、Deepseek 这样的工具的时候,我们是没办法设置系统提示词的。这类工具会使用一个默认的系统提示词,比如设定为”一个人工智能助手,请用严谨且高效的方式回答用户的问题”。但一般大语言模型公司都会提供一些 API 接口,所谓 API 接口就是让其他用户可以通过编程的方式来调用这些大模型,这个时候我们就可以自定义系统提示词了。比如我们开发一个教育的人工智能助手,那我们可以给模型提供一个系统提示词,告诉它“你是一个小学老师,请用通俗易懂的方式来回答学生的问题。” 这样模型就会使用更符合小学老师的风格来回答问题了。
大语言模型为什么能思考
去年在 Deepseek 出现之后,Deepseek 提供了一个叫深度思考的功能,很多人觉得它非常神奇。这个思考过程并没有脱离我们以上讲的内容的框架,它依然是基于前文来预测后文的一种机制。在训练模型的过程中,我们会给模型提供一些思考的内容,比如下面的例子:
输入:
已知 x + y = 10 且 x - y = 2,求 x 和 y 的值。输出:
<think>
这是一个二元一次方程组。
方程1: x + y = 10
方程2: x - y = 2
我们可以将两个方程相加来消去 y:
(x + y) + (x - y) = 10 + 2
2x = 12
x = 6
将 x = 6 代入方程1:
6 + y = 10
y = 4
最后验证一下方程2:6 - 4 = 2,完全正确。
解得 x=6, y=4。
</think>
通过联立方程组求解,得出结果为:x = 6,y = 4。上面的例子中,给定一个问题之后。模型的输出中包含了一个 <think> 标签。<think> </think> 标签中包含了模型的思考过程。这些思考的内容通常不是人工标注的,而是采用某些算法生成出来的。比如尝试让一个程序来解方程,它在解的过程中,会持续输出自己的解题步骤,最终这个题被解答出来了,那么整个解答步骤就可以通过文本描述出来。这些解题步骤就可以当做一个思考的过程,用来训练模型。
当模型使用了这种包含 think 标签的训练数据进行训练之后,在实际使用的时候,我们就可以让模型启动 think 模式。对于不需要思考的过程,可以在样本中将 think 内容设置为空,比如:
输入:
今天天气很好,适合出去玩。输出:
<think></think>
是啊,今天天气真的很好,你有什么计划吗?模型在使用的时候,如果我们想让它思考。我们就可以在输入中加入 <think> 标签,如果不想思考了,我们就可以在输入中加入 <think></think> 标签。加什么样的标签,取决于你在使用助手时是否打开了深度思考模式。
比如当你打开了深度思考模式之后,你输入的文本就会被包装成下面这样的格式:
<|im_start|>system
你是一个资深的 Python 架构师,请用严谨且高效的代码回答用户的问题。<|im_end|>
<|im_start|>user
如何快速反转一个列表?<|im_end|>
<|im_start|>assistant
<think>因为大模型就是在做文字的接龙,它处理完 <think> 这个标签之后,就会继续输出它的思考内容,直到输出 </think> 这个标签为止。模型输出内容可能如下:
用户想知道 Python 中反转列表最高效的方法。
1. 可以用 slice [::-1],速度最快但会创建新列表。
2. 可以用 .reverse(),原地修改,节省内存。
3. 应该把这两种都写出来并对比。
</think>
在 Python 中,反转列表主要有以下两种高效的方法:...<|im_end|>模型首先输出了 think 的内容,接着输出了它的回答。
而如果你没有打开深度思考模式,那么你输入的文本就会被包装成下面这样的格式:
<|im_start|>system
你是一个资深的 Python 架构师,请用严谨且高效的代码回答用户的问题。<|im_end|>
<|im_start|>user
如何快速反转一个列表?<|im_end|>
<|im_start|>assistant
<think></think>这里模型在处理完 </think> 这个标签之后,就会直接输出回答了,而不会输出思考的内容了。
总结来说,本质上就是通过 <think> 标签的开启和关闭来控制模型是否输出思考的内容了。
注:<think> 是标签的开始,</think> 是标签的结束。
大语言模型为什么需要联网搜索
在使用一些 AI 助手的时候,我们问了一个问题之后,通常会看到页面提示正在搜索网页。大模型难道真的有这种能力去打开浏览器搜索网页吗?其实它并没有这种能力。大语言模型在训练完成之后,它已经具备了基于前文来预测后文的能力。模型并不存在任何具体的事实,它只是掌握了语言的规律和模式。模型虽然能够回应任何问题,但这些问题并不一定都能正确地被回答。
前面我也提到,现在主流的大语言模型的参数量有几百 GB,难道大语言模型能够把这世间所有知识压缩到这几百 GB 参数里面吗?这显然是不可能的,这世间的所有知识是远远大于几百 GB 的。大语言模型并不是把这些知识或者事实全都记录了下来。大模型只能基于当前上下文输出一个符合语法规律和一般事实规律的回答。
早些年间,在使用大语言模型的时候,经常发现模型会输出一些错误的回答。比如问他鲁智深和林黛玉是什么关系?模型会一本正经地胡说八道。它可能会说鲁智深和林黛玉是表兄妹关系,或者说他们是夫妻关系,或者说他们是师兄妹关系等等。人们称这种现象为模型出现了“幻觉”。虽然这些回答都是错误的,但它们都是符合语法规律的,还存在一定的合理性,因为两个异性角色之间确实存在表兄妹关系、夫妻关系、师兄妹关系等等。
假如当我们输入一个问题,问模型“鲁智深和林黛玉是什么关系?” 时,我们可以通过关键字进行搜索,检索出关于鲁智深和林黛玉的信息。通过联网搜索之后,我们会得到以下信息:
- 鲁智深是水浒传中的人物
- 林黛玉是红楼梦中的人物
- 水浒传是施耐庵写的一部小说
- 红楼梦是曹雪芹写的一部小说
我们可以把这些信息连同用户问题输入给大模型:
<|im_start|>system
你是一个人工智能助手,请基于用户提供的信息回答用户的问题。如果你无法回答,请直接告诉用户你无法回答,不要编造任何信息。
<|im_end|>
<|im_start|>user
下面是上下文信息:
---------------------
[文档 1: 鲁智深是水浒传中的人物]
[文档 2: 林黛玉是红楼梦中的人物]
[文档 3: 水浒传是施耐庵写的一部小说]
[文档 4: 红楼梦是曹雪芹写的一部小说]
---------------------
请基于以上信息来回答以下问题:
问题: 鲁智深和林黛玉是什么关系?
<|im_end|>当模型收到这个输入之后,它就可以判断出鲁智深和林黛玉没有直接关系,因为他们分别属于不同的小说作品。这就像是模型在做一个阅读理解的题目一样,模型通过阅读这些文档,并基于自己掌握的语言规律来判断出林黛玉和鲁智深没有直接关系。因此模型就会输出“鲁智深和林黛玉没有直接关系,他们分别属于不同的小说作品。” 这样一个正确的回答了。
联网搜索就是在你的问题提交给大模型之前,这些对话系统的后台服务会先基于你的问题进行搜索,检索出一些相关的信息,然后把这些信息和你的问题一起输入给大模型,让大模型基于这些信息来回答你的问题。模型虽然不记录任何事实,但它能够结合输入的参考信息来回答用户的问题。
总结
最近这几年大语言模型非常火热,身边的人都在讨论和使用大语言模型,用它来帮助自己完成日常工作。逢年过节,一些亲戚朋友也会讨论这些人工智能助手,对此感觉到非常的神奇。大语言模型是一个非常复杂的技术,当下有很多最杰出的人才都在这个领域中探索,很多公司投入重金在这个领域开展研究,试图进一步提升模型的能力,提供更强的人工智能系统。
在这个周末,我试图以通俗易懂的语言来解释什么是大语言模型,避免了一些技术的细节。希望非计算机专业或对大语言模型不太了解的读者,也能够对大语言模型建立一个初步的认识。我认为当下这个时代,人们应该积极地去使用大语言模型帮助自己解决问题。对于绝大多数人而言,其实没有必要了解那么多的技术细节,只需要知道大概原理就够了。大多数人需要做的是用好大语言模型,用好智能助手来帮助自己解决生活中的问题,提高自己的工作效率。
说实在的,当我写完这篇文章之后,我会怀疑,对于了解大语言模型的人,他会觉得这篇文章的内容太简单了。而对于不了解大语言模型的人而言,这篇文章内容可能又过于复杂了。无论如何,我都希望这篇文章能够为读者提供一些帮助,如果你认为有哪些点是我遗漏的或有错误的,或者存在你没有明白的地方,可以通过留言告诉我。
注:文中部分图片使用 ChatGPT 生成,文字内容完全由作者原创。